Time Series Analysis in Python
Time Series data is a set of observations on the values that a variable takes at different times. Such data may be collected at regular time intervals such as hourly,daily,weekly,monthly,quaterly,anually etc.
The difference of time period between two observations would be equal throughout. i.e. t2-t1 = t3-t2
The dataset under study is a univariate time series data of passenger traffic count of a new transportation service. We need to forecast the passenger traffic for the next period using time series analysis.
Importing necessary modules
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
#plt.style.use('fivethirtyeight')
from dateutil.relativedelta import relativedelta
import warnings
warnings.filterwarnings('ignore')
%matplotlib inline
##Evaluation metrics
from sklearn.metrics import r2_score, median_absolute_error, mean_absolute_error
from sklearn.metrics import median_absolute_error, mean_squared_error, mean_squared_log_error
df = pd.read_csv(‘https://query.data.world/s/q5bzucmgamlgxet2hyev3366le6iu6’) df[‘dt’] = pd.to_datetime(df[‘Month’],format=’%Y-%m’) df.rename(columns={‘Monthly car sales in Quebec 1960-1968’:’count’},inplace=True) df.set_index(‘dt’,inplace=True)
Loading csv data into Pandas dataframe
df_train_raw = pd.read_csv('Train_SU63ISt.csv')
df_test_raw = pd.read_csv('Test_0qrQsBZ.csv')#Test_0qrQsBZ.csv
df_train_raw.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 18288 entries, 0 to 18287
Data columns (total 3 columns):
ID 18288 non-null int64
Datetime 18288 non-null object
Count 18288 non-null int64
dtypes: int64(2), object(1)
memory usage: 428.7+ KB
We first convert the ‘Datetime’ column into pandas datetime datatype and we’ll create new features such as year,month,day,hour,day of week and weekend/weekday flags using the below user defined functions.
def weekend_flag(row):
if row.day_of_week==5 or row.day_of_week==6:
return 1
else:
return 0
def data_prep(df):
df.index = pd.to_datetime(df.Datetime,format='%d-%m-%Y %H:%M')
df.Datetime = pd.to_datetime(df.Datetime,format='%d-%m-%Y %H:%M')
df['year'] = df.Datetime.dt.year
df['month'] = df.Datetime.dt.month
df['day'] = df.Datetime.dt.day
df['hour'] = df.Datetime.dt.hour
df['day_of_week'] = df.Datetime.dt.dayofweek
df['weekend'] = df.apply(weekend_flag,axis=1)
df = df.drop(['Datetime','ID'],axis=1)
return df
df_train_all = data_prep(df_train_raw)
df_test = data_prep(df_test_raw)
df_train_all.head()
| Count | year | month | day | hour | day_of_week | weekend | |
|---|---|---|---|---|---|---|---|
| Datetime | |||||||
| 2012-08-25 00:00:00 | 8 | 2012 | 8 | 25 | 0 | 5 | 1 |
| 2012-08-25 01:00:00 | 2 | 2012 | 8 | 25 | 1 | 5 | 1 |
| 2012-08-25 02:00:00 | 6 | 2012 | 8 | 25 | 2 | 5 | 1 |
| 2012-08-25 03:00:00 | 2 | 2012 | 8 | 25 | 3 | 5 | 1 |
| 2012-08-25 04:00:00 | 2 | 2012 | 8 | 25 | 4 | 5 | 1 |
print('Train data time period --- Start:',df_train_all.index.min().strftime('%D %H:%M:%S'))
print('Train data time period --- End:',df_train_all.index.max().strftime('%D %H:%M:%S'))
Train data time period --- Start: 08/25/12 00:00:00
Train data time period --- End: 09/25/14 23:00:00
print('Test data time period --- Start:',df_test.index.min().strftime('%D %H:%M:%S'))
print('Test data time period --- End:',df_test.index.max().strftime('%D %H:%M:%S'))
Test data time period --- Start: 09/26/14 00:00:00
Test data time period --- End: 04/26/15 23:00:00
As we can see the train data comprises of hourly level passenger count data from 25th August 2012 to 25th September 2014. Using this data we need to perform time series forecasting for the test data for 7 months from September 26th 2014 to 26th April 2015 using the last 25 month data.
Before moving into modelling the data we’ll perform data exploration to find patterns and may be support our hypothesis of factors which could affect the outcome which in our case is passenger inflow.
Exploratory Data Analysis
df = df_train_all.copy()
df_train = df
plt.figure(figsize=(16, 9))
plt.plot(df_train['Count'],label='train')
plt.grid(True)
plt.legend()
<matplotlib.legend.Legend at 0x7f0ccee447b8>
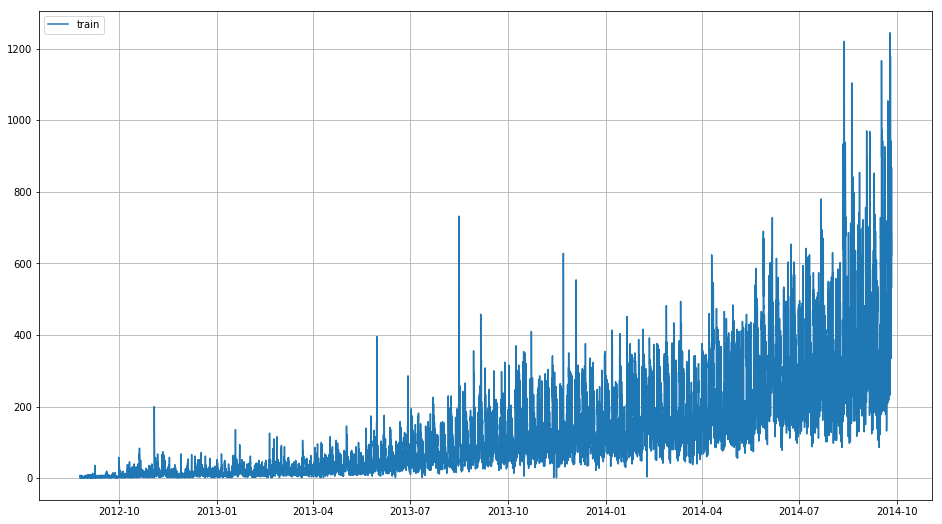
Due to hourly collected data we are seeing irregularities and unable to see clear patterns in our data but we can infer here that our data has some increasing trend.In terms of seasonality and cyclic trend it is difficult to check in this plot.Therefore we will resample our data on daily,weekly,monthly and yearly level and visualize to understand the patterns.
fig,ax = plt.subplots(5,1,figsize=(14,10))
axs = ax.flatten()
axs[0].plot(df_train['Count'])
axs[1].plot(df_train['Count'].resample('D'))
axs[2].plot(df_train['Count'].resample('W'))
axs[3].plot(df_train['Count'].resample('M'))
axs[4].plot(df_train['Count'].resample('Y'))
axs[0].set_title('Hourly')
axs[1].set_title('Daily')
axs[2].set_title('Weekly')
axs[3].set_title('Monthly')
axs[4].set_title('Yearly')
plt.tight_layout()
plt.show()
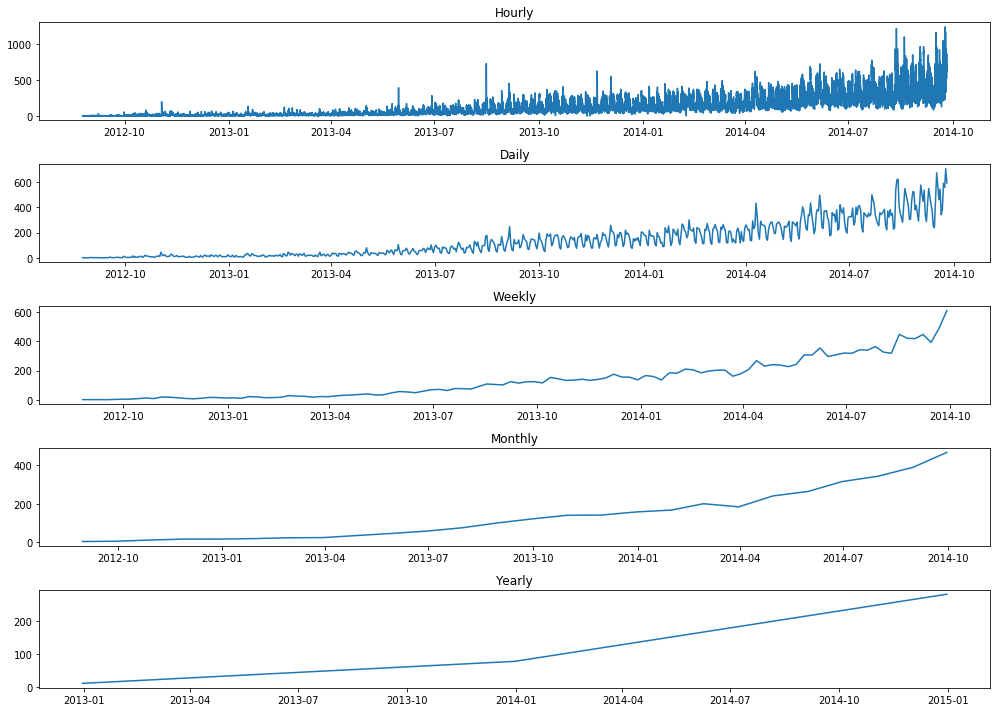
plt.figure(figsize=(15,5))
plt.plot(df_train['Count'].resample('D'))
plt.xlim('2014-03','2014-06')
plt.show()
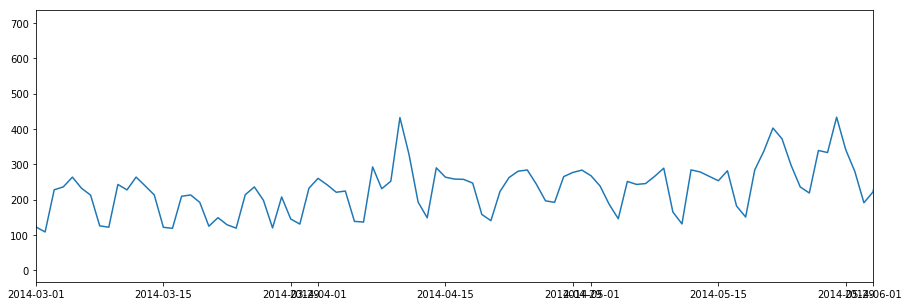
On resampling at a daily level we can clearly see trend and seasonal patterns emerging from our data.We would use our daily resampled time series data for modelling as it has lesser noise compared to hourly data.
No we’ll check our hypothesis on whether the weekend would have higher passenger count compared to weekdays and how other date related features affect the passenger count. We plot the aggregated data to check the passenger inflow varies depending on features such as day of week,hour of day,weekend/weekday and year levels.
fig,ax = plt.subplots(2,3,figsize=(16, 8))
df_train.groupby(['year']).agg({'Count':np.mean}).plot(kind='bar',ax=ax[0][0])
df_train.groupby(['month']).agg({'Count':np.mean}).plot(kind='bar',ax=ax[0][1])
df_train.groupby(['day']).agg({'Count':np.mean}).plot(kind='bar',ax=ax[0][2])
df_train.groupby(['hour']).agg({'Count':np.mean}).plot(kind='bar',ax=ax[1][0])
df_train.groupby(['day_of_week']).agg({'Count':np.mean}).plot(kind='bar',ax=ax[1][1])
df_train.groupby(['weekend']).agg({'Count':np.mean}).plot(kind='bar',ax=ax[1][2])
fig.suptitle('Aggregated passenger count values based on date features',size=16)
plt.tight_layout()
fig.subplots_adjust(top=0.88)
plt.show()
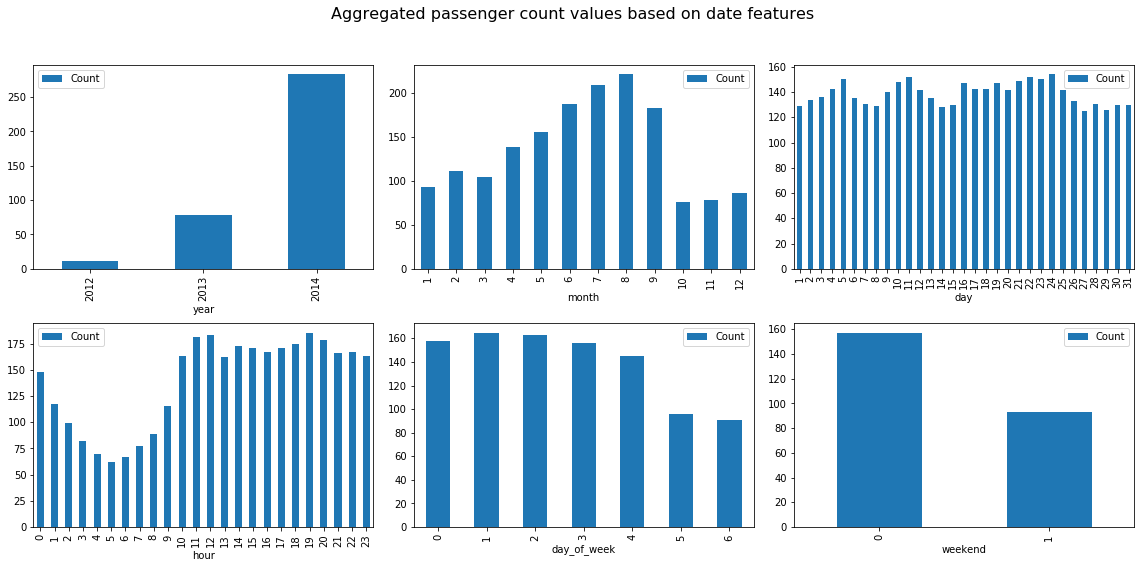
We can infer a lot of information from these plots on how the passenger inflow varies on different levels. The passenger inflow has drastically increased on an average compared to previous two years and July/August months have higher passengers compared to other months due to holiday season in this area.On a hourly basis it is clear the passengers count increases from 9AM and coninues thoroughout the day only to gradually decrease after midnight. Suprisingly the passenger inflow in much higher on weekdays compared to weekend which can be attributed to working days and hence large proportion of people using this transportation for work commute.
Box plot to check the contribution % of hourly level and daily level granularity.
Here we calculate the contribution% of each hour compared to the whole day and simillarly calculate the contribution% of each day within each fiscal week,finally we plot these contributions using box plot to check if there are significant differences of each hours contribution or day of the week contribution.
df = df_train_all.copy()
def fiscal_day(row):
return str(str(row.year)+str(row.month)+str(row.day))
df['fiscal_day'] = df.apply(fiscal_day,axis=1)
df['daily_sum_count'] = df.groupby(['fiscal_day'])['Count'].transform('sum')
df["hour_weight"] = df.Count / df.daily_sum_count
df["hour_weight"] *= 100
import seaborn as sns
sns.set_style('ticks')
fig, ax = plt.subplots()
fig.set_size_inches(11.7, 8.27)
sns.boxplot(x='hour', y='hour_weight', data=df.sort_values(by=['hour_weight'],ascending=False)[1:],whis=np.inf)
#sns.violinplot(x='hour', y='hour_weight', data=df,whis=np.inf)
#sns.stripplot(x='hour', y='hour_weight', data=df, jitter=True, color=".3")
plt.ylabel("Contribution %")
sns.despine()
plt.show()
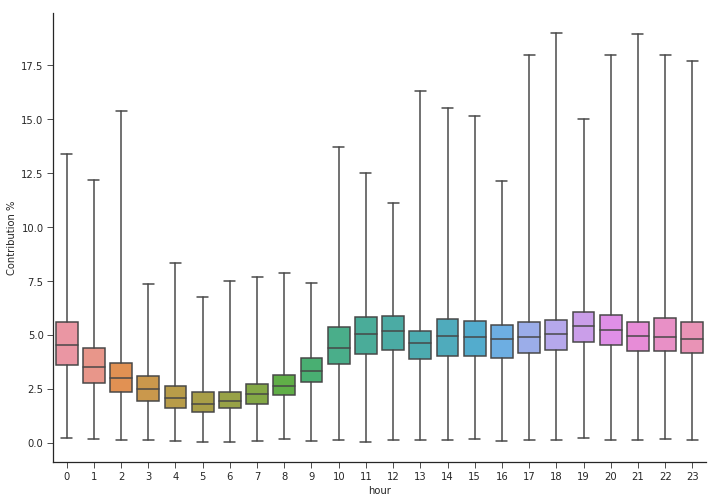
It is clear from this plot that the passenger counts decline from 12AM gradually till 5AM and later picks up from 7AM to 10AM after which the passenger inflow is considerably high through out till 11PM.
df = df_train_all.copy()
df = df.resample('D').mean()
df['week_no'] = df.index.weekofyear
df['week_no'] = df['week_no'].apply(lambda x:str(x).split('.')[0])
df['year'] = df['year'].apply(lambda x: str(x).split('.')[0])#(df_day.groupby("week")["consumption"].transform(sum))
def fiscal_week(row):
return str(str(row.year)+str(row.week_no))
df['fiscal_week_id'] = df.apply(fiscal_week,axis=1)
df['weekly_sum_count'] = df.groupby(['fiscal_week_id'])['Count'].transform('sum')
df["week_weight"] = df.Count / df.weekly_sum_count
df["week_weight"] *= 100
df["day_name"] = df.index.map(lambda x: x.strftime("%A"))
import seaborn as sns
sns.set_style('ticks')
fig, ax = plt.subplots()
# the size of A4 paper
fig.set_size_inches(11.7, 8.27)
sns.boxplot(x='day_name', y='week_weight', data=df,whis=np.inf)
sns.violinplot(x='day_name', y='week_weight', data=df,whis=np.inf)
sns.stripplot(x='day_name', y='week_weight', data=df, jitter=True, color=".3")
plt.ylabel("Contribution %")
sns.despine()
plt.show()
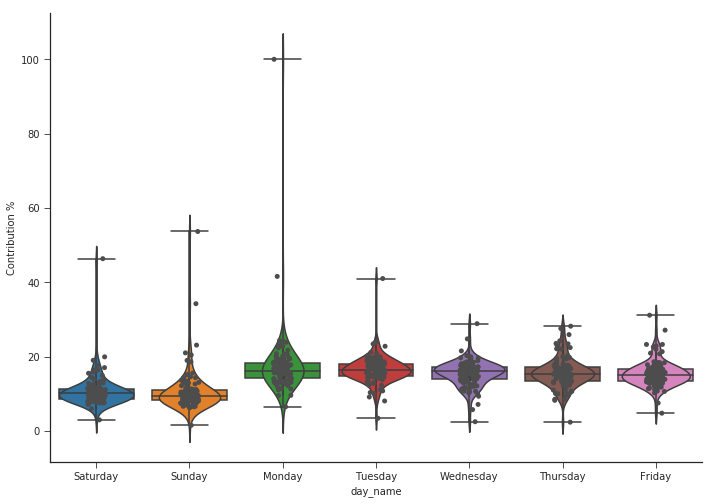
We can clearly infer more passenger counts during weekdays compared to weekends as we had seen earlier.1
####
df_train = df_train.resample('D').mean()
df_test = df_test.resample('D').mean()
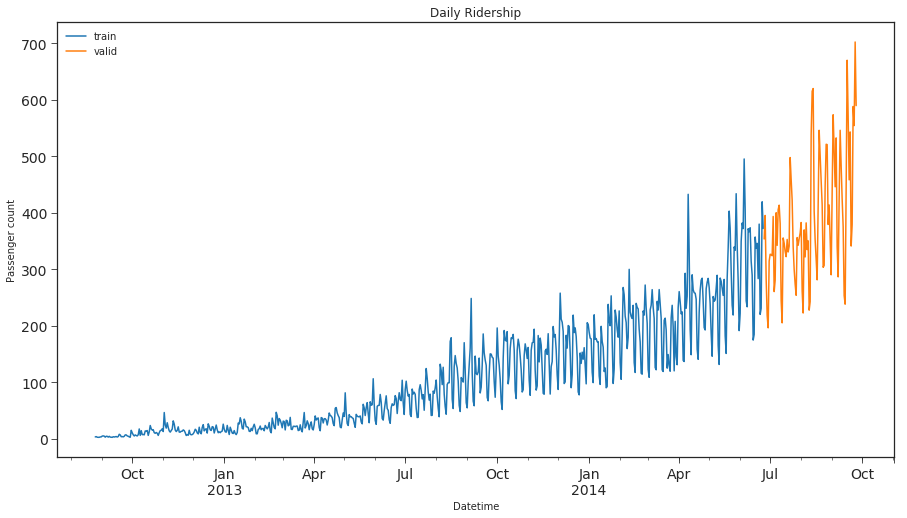
### SPLITING DATA INTO TRAINING AND VALIDATION PART
Train=df_train.ix['2012-08-25':'2014-06-24']
valid=df_train.ix['2014-06-25':'2014-09-25']
### Now we will look at how the train and validation part has been divided.
Train.Count.plot(figsize=(15,8), title= 'Daily Ridership', fontsize=14, label='train')
valid.Count.plot(figsize=(15,8), title= 'Daily Ridership', fontsize=14, label='valid')
plt.xlabel("Datetime")
plt.ylabel("Passenger count")
plt.legend(loc='best')
plt.show()
def mean_absolute_percentage_error(y_true, y_pred):
return np.mean(np.abs((y_true - y_pred) / y_true)) * 100
from sklearn.metrics import r2_score, median_absolute_error, mean_absolute_error
from sklearn.metrics import median_absolute_error, mean_squared_error, mean_squared_log_error
Data stationarity
A time series Y_t (t=1,2…) is said to be stationary (in the weak sense) if its statistical properties do not vary with time (expectation, variance, autocorrelation). The white noise is an example of a stationary time series, with for example the case where Y_t follows a normal distribution N(mu, sigma^2) independent of t.
Identifying that a series is not stationary allows to afterwards study where the non-stationarity comes from. A non-stationary series can, for example, be stationary in difference (also called integrated of order 1): Y_t is not stationary, but the Y_t - Y_{t-1} difference is stationary. It is the case of the random walk. A series can also be stationary in trend.
Stationarity tests allow verifying whether a series is stationary or not. There are two different approaches: stationarity tests such as the KPSS test that consider as null hypothesis H0 that the series is stationary, and unit root tests, such as the Dickey-Fuller test and its augmented version, the augmented Dickey-Fuller test (ADF), or the
Weak stationarity means that the first and second moments (so the mean, variance, and autocovariance) don’t change with time. A strongly stationary process has the same distribution no matter the time, but let’s focus on the weakly stationary process, as any strongly stationary process is weakly stationary.
Because when estimating the mean and variance of your data, non stationarity will bias those estimates. Forecasting will be much worse, and the estimates of correlation and covariance will be unreliable.
Moving averages should be calculated when the mean is as fixed as possible.
Stationarity is defined uniquely, i.e. data is either stationary or not, so there is only way for data to be stationary, but lots of ways for it to be non-stationary. Again it turns out that a lot of data becomes stationary after certain transformation. ARIMA model is one model for non-stationarity. It assumes that the data becomes stationary after differencing.
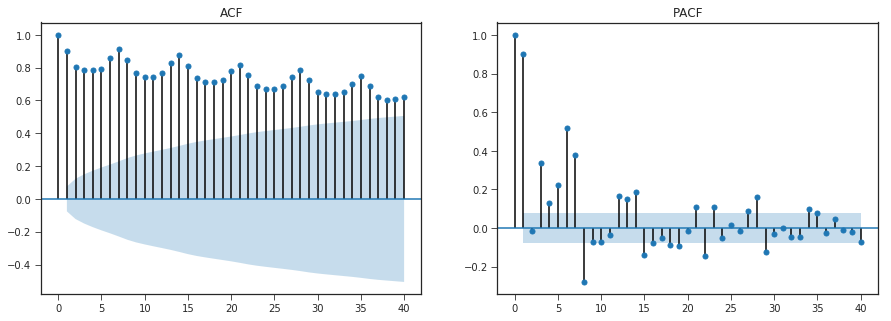
Autocorrelation and Partial Autocorrelation
• The autocorrelation function (ACF) plot shows the
correlation of the series with itself at different lags
– The autocorrelation of Y at lag k is the correlation between
Y and LAG(Y,k)
• The partial autocorrelation function (PACF) plot
shows the amount of autocorrelation at lag k that is
not explained by lower-order autocorrelations
– The partial autocorrelation at lag k is the coefficient of
LAG(Y,k) in an AR(k) model, i.e., in a regression of Y on
LAG(Y, 1), LAG(Y,2), … up to LAG(Y,k)
• ACF that dies out gradually and PACF that cuts off
sharply after a few lags AR signature
– An AR series is usually positively autocorrelated at lag 1
(or even borderline nonstationary)
• ACF that cuts off sharply after a few lags and PACF
that dies out more gradually MA signature
– An MA series is usually negatively autcorrelated at lag 1
(or even mildly overdifferenced)
#from statsmodels.tsa.stattools import acf,pacf
import matplotlib.pylab as plt
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
data = Train['Count']
#acf = acf(data, nlags=40)
#pacf = pacf(data,nlags=40,method='ols')
#plt.stem(acf)
fig,ax = plt.subplots(1,2,figsize=(15,5))
plot_acf(data,lags=40,title="ACF",ax=ax[0])
#plt.show()
plot_pacf(data,lags=40,title="PACF",ax=ax[1])
plt.show()
data1 = data.diff(periods=1).values[1:]
fig,ax = plt.subplots(1,2,figsize=(15,5))
plot_acf(data1,lags=40,title="ACF",ax=ax[0])
#plt.show()
plot_pacf(data1,lags=40,title="PACF",ax=ax[1])
plt.show()
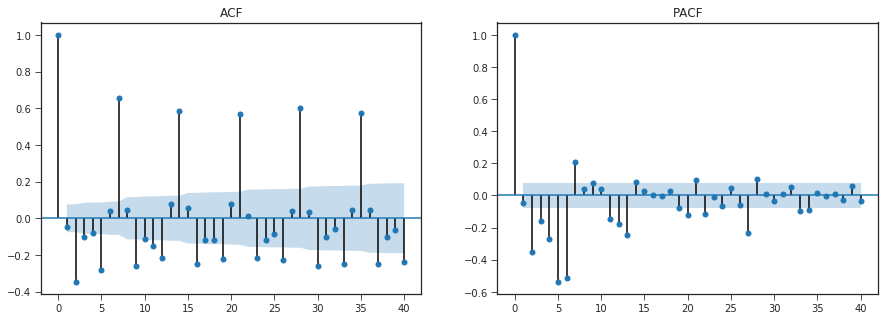
ACF - As all lags are close to 1 or atleast greater than confidence interval ,autocorrelation is statisitically significant.
PACF -
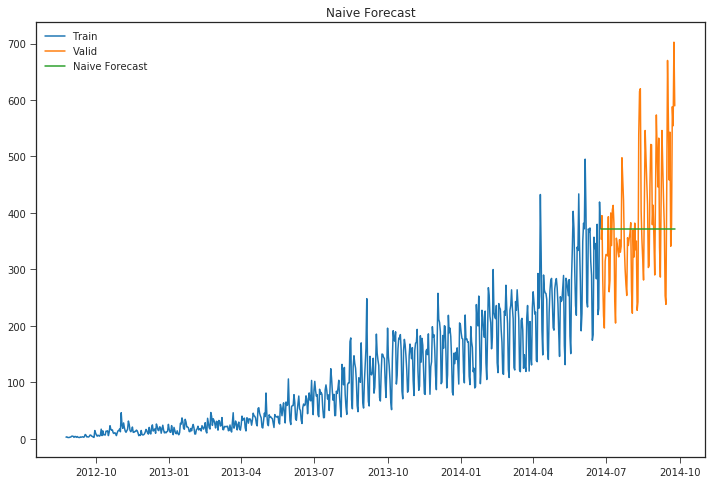
1. NAIVE APPROACH
In this forecasting technique, we assume that the next expected point is equal to the last observed point. So we can expect a straight horizontal line as the prediction:
trn_cnt= np.asarray(Train.Count)
y_hat = valid.copy()
y_hat['naive'] = trn_cnt[len(trn_cnt)-1]
plt.figure(figsize=(12,8))
plt.plot(Train.index, Train['Count'], label='Train')
plt.plot(valid.index,valid['Count'], label='Valid')
plt.plot(y_hat.index,y_hat['naive'], label='Naive Forecast')
plt.legend(loc='best')
plt.title("Naive Forecast")
plt.show()
print("r2_score >>>",r2_score(y_hat['Count'], y_hat['naive']))
print("mean_absolute_percentage_error >>>",mean_absolute_percentage_error(y_hat['Count'], y_hat['naive']))
print("median_absolute_error >>>",median_absolute_error(y_hat['Count'], y_hat['naive']))
print("mean_absolute_error >>>",mean_absolute_error(y_hat['Count'], y_hat['naive']))
print("mean_squared_error >>>",mean_squared_error(y_hat['Count'], y_hat['naive']))
print("mean_squared_log_error >>>",mean_squared_log_error(y_hat['Count'], y_hat['naive']))
r2_score >>> -0.02404216991538255
mean_absolute_percentage_error >>> 22.91834464294656
median_absolute_error >>> 65.5
mean_absolute_error >>> 86.68458781362007
mean_squared_error >>> 12497.116935483871
mean_squared_log_error >>> 0.07875605388878908
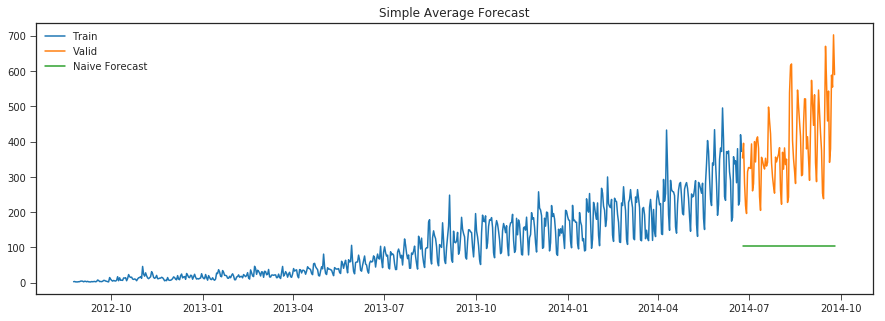
Simple Average
trn_cnt= np.asarray(Train.Count)
y_hat = valid.copy()
y_hat['avg'] = trn_cnt.mean()
plt.figure(figsize=(15,5))
plt.plot(Train.index, Train['Count'], label='Train')
plt.plot(valid.index,valid['Count'], label='Valid')
plt.plot(y_hat.index,y_hat['avg'], label='Naive Forecast')
plt.legend(loc='best')
plt.title("Simple Average Forecast")
plt.show()
print("r2_score >>>",r2_score(y_hat['Count'], y_hat['avg']))
print("mean_absolute_percentage_error >>>",mean_absolute_percentage_error(y_hat['Count'], y_hat['avg']))
print("median_absolute_error >>>",median_absolute_error(y_hat['Count'], y_hat['avg']))
print("mean_absolute_error >>>",mean_absolute_error(y_hat['Count'], y_hat['avg']))
print("mean_squared_error >>>",mean_squared_error(y_hat['Count'], y_hat['avg']))
print("mean_squared_log_error >>>",mean_squared_log_error(y_hat['Count'], y_hat['avg']))
r2_score >>> -6.662202498647111
mean_absolute_percentage_error >>> 71.04725322248096
median_absolute_error >>> 260.00884404583957
mean_absolute_error >>> 285.1378763039041
mean_squared_error >>> 93507.32169248654
mean_squared_log_error >>> 1.6971961068304557
Moving Average
Let’s start with a naive hypothesis: “tomorrow will be the same as today”. However, instead of a model like y^t=yt−1y^t=yt−1 (which is actually a great baseline for any time series prediction problems and sometimes is impossible to beat), we will assume that the future value of our variable depends on the average of its kk previous values. Therefore, we will use the moving average.
y^t=yt−1
#rolling_mean = Train['count'].rolling(2).mean()
def moving_average_predict_plot(window):
rolling_mean_train = Train['Count'].rolling(window).mean()
rolling_mean_valid = valid['Count'].rolling(window).mean()
plt.figure(figsize=(15, 5))
plt.plot(df['Count'],label='original')
plt.plot(Train['Count'],label='train')
plt.plot(rolling_mean_train,label='train_rolling_mean_{}'.format(str(window)))
#mea = mean_absolute_error(Train['count'][2:],rolling_mean[2:])
#sd = np.std(df['count'][2:] - rolling_mean[2:])
#cf_up = rolling_mean + (mea + (1.96*sd))
#cf_low = rolling_mean - (mea+(1.96*sd))
#plt.plot(cf_up,'r--')
#plt.plot(cf_low,'r--')
#mea = mean_absolute_error(valid['Count'][window:],rolling_mean_valid[window:])
#sd = np.std(valid['Count'][window:] - rolling_mean_valid[window:])
#cf_up = rolling_mean + (mea + (1.96*sd))
#cf_low = rolling_mean - (mea+(1.96*sd))
#plt.plot(cf_up,'r--')
#plt.plot(cf_low,'r--')
plt.plot(rolling_mean_valid,label='valid_rolling_mean_{}'.format(str(window)))
plt.title('Moving average - window:{}'.format(str(window)))
plt.grid(True)
plt.legend()
plt.show()
print( 'RMSE:',np.sqrt(mean_squared_error(valid['Count'][window:],rolling_mean_valid[window:])))
moving_average_predict_plot(10)
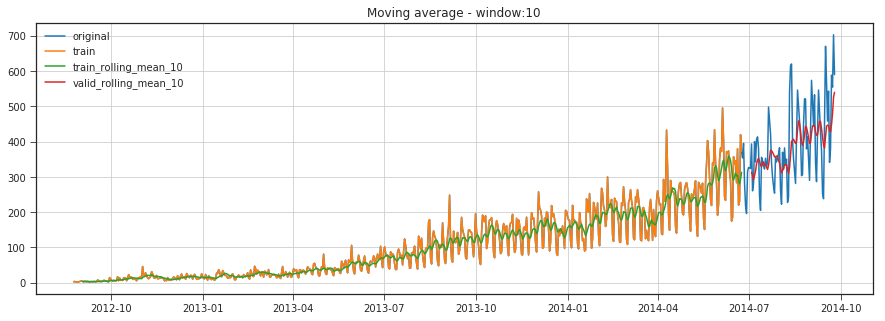
RMSE: 90.9914913199977
moving_average_predict_plot(5)
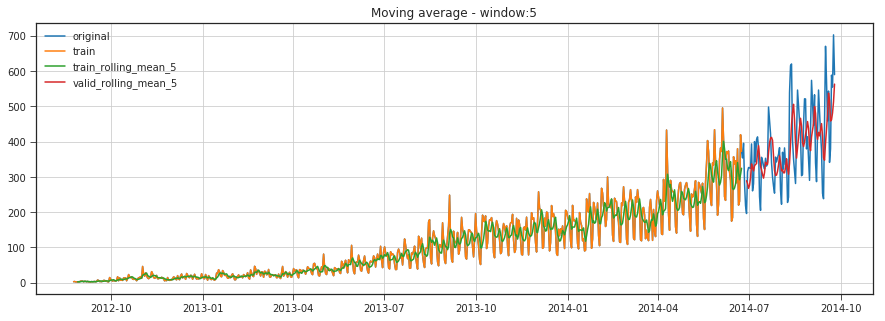
RMSE: 94.86415250533551
moving_average_predict_plot(60)
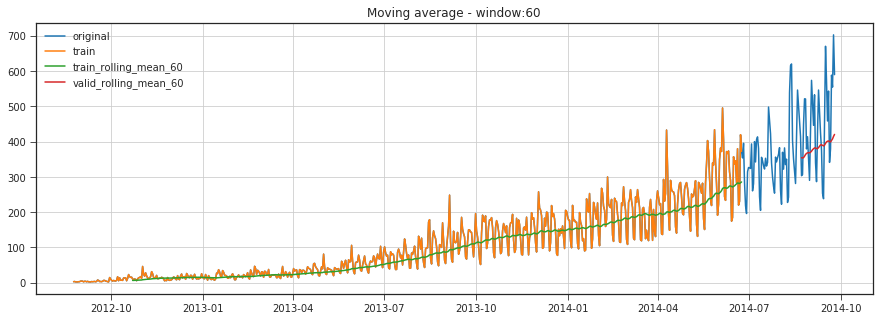
RMSE: 129.40415262528867
Unfortunately, we cannot make predictions far in the future – in order to get the value for the next step, we need the previous values to be actually observed. But moving average has another use case - smoothing the original time series to identify trends. Pandas has an implementation available with DataFrame.rolling(window).mean(). The wider the window, the smoother the trend. In the case of very noisy data, which is often encountered in finance, this procedure can help detect common patterns.
In real-world scenarios our prediction would be as below as we would not know in prior the previous value observed.
y_hat_avg = valid.copy()
y_hat_avg['moving_avg_forecast'] = Train['Count'].rolling(10).mean().iloc[-1] # average of last 10 observations.
plt.figure(figsize=(15,5))
plt.plot(Train['Count'], label='Train')
plt.plot(valid['Count'], label='Valid')
plt.plot(y_hat_avg['moving_avg_forecast'], label='Moving Average Forecast using 10 observations')
plt.legend(loc='best')
plt.show()
print("r2_score >>>",r2_score(y_hat_avg['Count'], y_hat_avg['moving_avg_forecast']))
print("mean_absolute_percentage_error >>>",mean_absolute_percentage_error(y_hat_avg['Count'], y_hat_avg['moving_avg_forecast']))
print("median_absolute_error >>>",median_absolute_error(y_hat_avg['Count'], y_hat_avg['moving_avg_forecast']))
print("mean_absolute_error >>>",mean_absolute_error(y_hat_avg['Count'], y_hat_avg['moving_avg_forecast']))
print("mean_squared_error >>>",mean_squared_error(y_hat_avg['Count'], y_hat_avg['moving_avg_forecast']))
print("mean_squared_log_error >>>",mean_squared_log_error(y_hat_avg['Count'], y_hat_avg['moving_avg_forecast']))
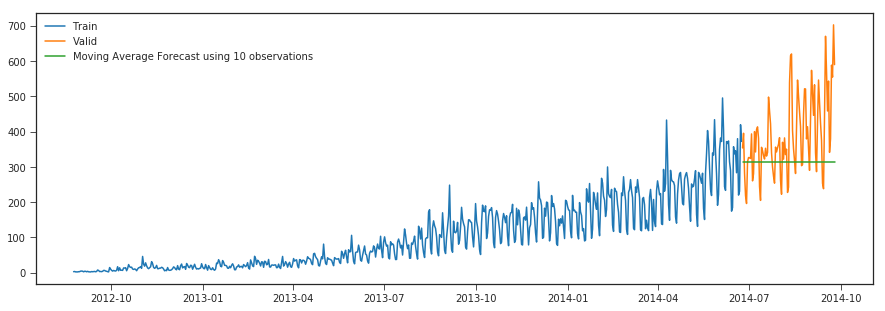
r2_score >>> -0.4765720330640295
mean_absolute_percentage_error >>> 23.402587178079358
median_absolute_error >>> 69.7166666666667
mean_absolute_error >>> 100.90824372759855
mean_squared_error >>> 18019.66159498208
mean_squared_log_error >>> 0.11046352508245877
Simple Exponential Smoothing
predictions are made by assigning larger weight to the recent values and lesser weight to the old values. When applied to time series forecasting the basic idea is to look at previous measurements and weight them according to how distant in the past they are, typically this decays exponentially the farther back in time you go so that older observations have less influence on the forecast
from statsmodels.tsa.api import ExponentialSmoothing, SimpleExpSmoothing, Holt
y_hat_avg = valid.copy()
fit2 = SimpleExpSmoothing(np.asarray(Train['Count'])).fit(smoothing_level=0.6,optimized=False)
y_hat_avg['SES'] = fit2.forecast(len(valid))
plt.figure(figsize=(15,5))
plt.plot(Train['Count'], label='Train')
plt.plot(valid['Count'], label='Valid')
plt.plot(y_hat_avg['SES'], label='SES')
plt.legend(loc='best')
plt.show()
print("r2_score >>>",r2_score(y_hat_avg['Count'], y_hat_avg['SES']))
print("mean_absolute_percentage_error >>>",mean_absolute_percentage_error(y_hat_avg['Count'], y_hat_avg['SES']))
print("median_absolute_error >>>",median_absolute_error(y_hat_avg['Count'], y_hat_avg['SES']))
print("mean_absolute_error >>>",mean_absolute_error(y_hat_avg['Count'], y_hat_avg['SES']))
print("mean_squared_error >>>",mean_squared_error(y_hat_avg['Count'], y_hat_avg['SES']))
print("mean_squared_log_error >>>",mean_squared_log_error(y_hat_avg['Count'], y_hat_avg['SES']))
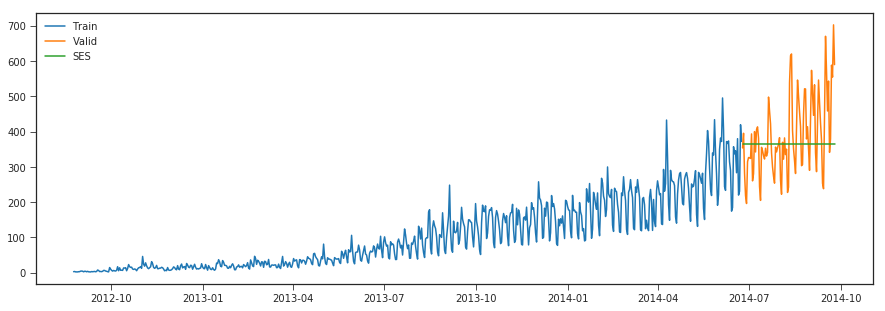
r2_score >>> -0.05443082552571954
mean_absolute_percentage_error >>> 22.35065218235077
median_absolute_error >>> 62.477507770932334
mean_absolute_error >>> 86.55172947423941
mean_squared_error >>> 12867.971372763452
mean_squared_log_error >>> 0.07956918735902696
Holt’s Linear Trend method
from statsmodels.tsa.api import ExponentialSmoothing, SimpleExpSmoothing, Holt
y_hat_avg = valid.copy()
fit2 = Holt(np.asarray(Train['Count'])).fit(smoothing_level = 0.2,smoothing_slope = 0.1)
y_hat_avg['holt_linear'] = fit2.forecast(len(valid))
plt.figure(figsize=(15,5))
plt.plot(Train['Count'], label='Train')
plt.plot(valid['Count'], label='Valid')
plt.plot(y_hat_avg['holt_linear'], label='holt_linear')
plt.legend(loc='best')
plt.show()
print("r2_score >>>",r2_score(y_hat_avg['Count'], y_hat_avg['holt_linear']))
print("mean_absolute_percentage_error >>>",mean_absolute_percentage_error(y_hat_avg['Count'], y_hat_avg['holt_linear']))
print("median_absolute_error >>>",median_absolute_error(y_hat_avg['Count'], y_hat_avg['holt_linear']))
print("mean_absolute_error >>>",mean_absolute_error(y_hat_avg['Count'], y_hat_avg['holt_linear']))
print("mean_squared_error >>>",mean_squared_error(y_hat_avg['Count'], y_hat_avg['holt_linear']))
print("mean_squared_log_error >>>",mean_squared_log_error(y_hat_avg['Count'], y_hat_avg['holt_linear']))
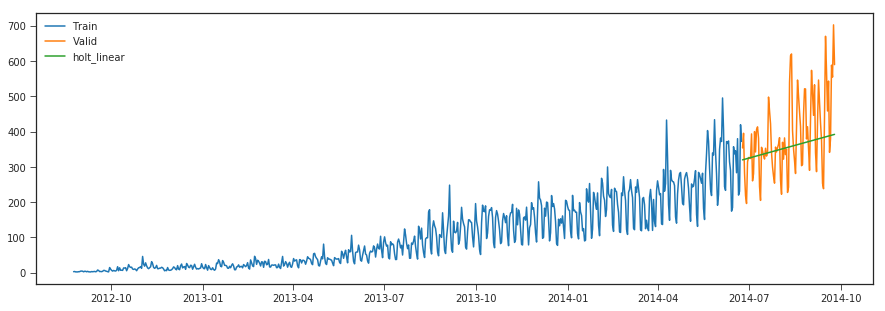
r2_score >>> 0.06943531380186796
mean_absolute_percentage_error >>> 20.325129883009378
median_absolute_error >>> 66.43587545533114
mean_absolute_error >>> 80.37510479716255
mean_squared_error >>> 11356.34453453304
mean_squared_log_error >>> 0.06855802909033636
This method only captures the linear trend in our data for forecasting wherease it misses out on capturing the multiplicative seasonal pattern.
#### Holt-Winters Method
from statsmodels.tsa.api import ExponentialSmoothing, SimpleExpSmoothing, Holt
y_hat_avg = valid.copy()
fit2 = ExponentialSmoothing(np.asarray(Train['Count']),seasonal_periods=7 ,trend='add', seasonal='add').fit()
y_hat_avg['holt_winters'] = fit2.forecast(len(valid))
plt.figure(figsize=(15,5))
plt.plot(Train['Count'], label='Train')
plt.plot(valid['Count'], label='Valid')
plt.plot(y_hat_avg['holt_winters'], label='holt_winters')
plt.legend(loc='best')
plt.show()
print("r2_score >>>",r2_score(y_hat_avg['Count'], y_hat_avg['holt_winters']))
print("mean_absolute_percentage_error >>>",mean_absolute_percentage_error(y_hat_avg['Count'], y_hat_avg['holt_winters']))
print("median_absolute_error >>>",median_absolute_error(y_hat_avg['Count'], y_hat_avg['holt_winters']))
print("mean_absolute_error >>>",mean_absolute_error(y_hat_avg['Count'], y_hat_avg['holt_winters']))
print("mean_squared_error >>>",mean_squared_error(y_hat_avg['Count'], y_hat_avg['holt_winters']))
print("mean_squared_log_error >>>",mean_squared_log_error(y_hat_avg['Count'], y_hat_avg['holt_winters']))
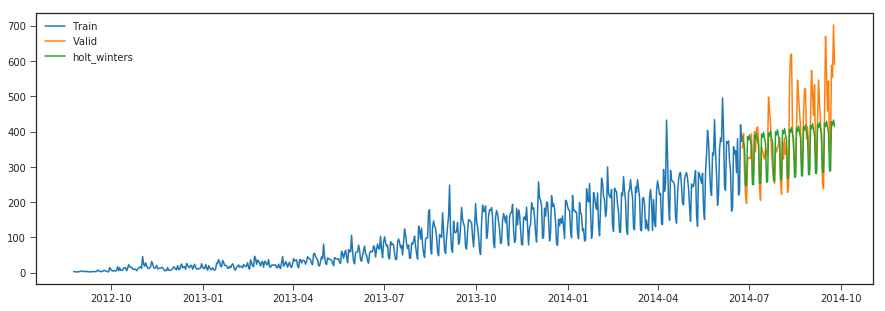
r2_score >>> 0.4439655242397562
mean_absolute_percentage_error >>> 14.298419970700103
median_absolute_error >>> 43.27903481717709
mean_absolute_error >>> 60.57966738353202
mean_squared_error >>> 6785.68526558865
mean_squared_log_error >>> 0.034678526680439636
The above methods doesn’t seem to capture the overall multiplicative seasonality and trend patterns in the data,on looking at the plot of the timeseries data we can see there is positive linear trend , multiplicative seasonal patterns and few irregular patterns,therefore we could use SARIMA model for our forecasting.
Time Series Decomposition.
Some distinguishable patterns appear when we plot the data. The time-series has an obvious multiplicative seasonality pattern, as well as an overall increasing trend. We can also visualize our data using a method called time-series decomposition. As its name suggests, time series decomposition allows us to decompose our time series into three distinct components: trend, seasonality, and noise.
Trend: A trend exists when there is a long-term increase or decrease in the data. It does not have to be linear. Sometimes we will refer to a trend “changing direction” when it might go from an increasing trend to a decreasing trend.
Seasonal: A seasonal pattern exists when a series is influenced by seasonal factors (e.g., the quarter of the year, the month, or day of the week). Seasonality always has a fixed and known period.
Cycles: A cyclic pattern exists when data exhibit rises and falls that are not from the fixed period. The duration of these fluctuations is usually of at least 2 years.
Noise: The random variation in the series.
import statsmodels.api as sm
from pylab import rcParams
rcParams['figure.figsize'] = 11, 9
import matplotlib.pyplot as plt
model=sm.tsa.seasonal_decompose(Train['Count'],model='additive')
fig = model.plot()
plt.show()
#fig, (ax1,ax2,ax3) = plt.subplots(3,1, figsize=(15,8))
#model.trend.plot(ax=ax1)
#model.seasonal.plot(ax=ax2)
#model.resid.plot(ax=ax3)
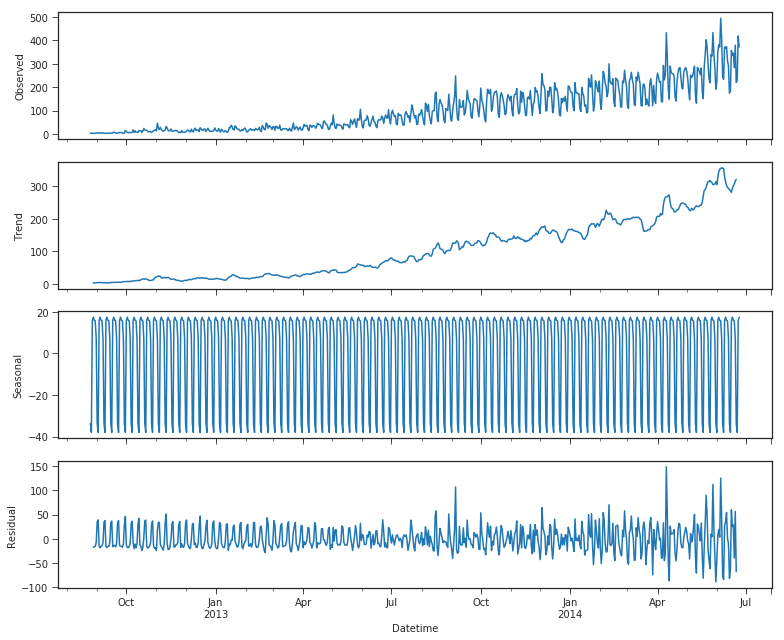
Using time-series decomposition makes it easier to quickly identify a changing mean or variation in the data. The plot above clearly shows the upwards trend of our data, along with its seasonality. These can be used to understand the structure of our time-series. The intuition behind time-series decomposition is important, as many forecasting methods build upon this concept of structured decomposition to produce forecasts.
Next since the data has multiplicative seasonality we apply a log filter and then analyze the residuals with autocorrelation plots.
data = Train['Count']
data = np.log(data)
data_diff = data.diff(periods=1).values[1:]
plt.plot(data_diff)
plt.gcf().set_size_inches(18,6)
Checking data stationarity
A stationary time series (TS) is simple to predict as we can assume that future statistical properties are the same or proportional to current statistical properties.
Most of the models we use in TSA assume covariance-stationarity (#3 above). This means the descriptive statistics these models predict e.g. means, variances, and correlations, are only reliable if the TS is stationary and invalid otherwise.
For example, if the series is consistently increasing over time, the sample mean and variance will grow with the size of the sample, and they will always underestimate the mean and variance in future periods. And if the mean and variance of a series are not well-defined, then neither are its correlations with other variables
from statsmodels.tsa.stattools import adfuller
print('Results of Dickey-Fuller Test:')
dftest = adfuller(df_train.Count, autolag='AIC')
dfoutput = pd.Series(dftest[0:4], index=['Test Statistic', 'p-value', '#lags Used', 'Number of Observations Used'])
for key, value in dftest[4].items():
dfoutput['Critical Value (%s)'%key] = value
print(dfoutput)
Results of Dickey-Fuller Test:
Test Statistic 2.986351
p-value 1.000000
#lags Used 20.000000
Number of Observations Used 741.000000
Critical Value (1%) -3.439206
Critical Value (5%) -2.865448
Critical Value (10%) -2.568851
dtype: float64
It is very clear from the p-value that this is not stationary and has varying statistical properties over time
ARIMA & SARIMA
One of the most communal modes used in time series forecasting is known as the ARIMA model, which stands for AutoregRessive Integrated Moving Average. ARIMA is a model that can be fitted to time series data in order to good understand or predict future points in the series.
There are three different numbers (p, d, q) that are used to parametrize ARIMA models. Because of that, ARIMA models are denoted with the notation ARIMA(p, d, q). Together these three parameters account for seasonality, trend, and sound in datasets:
p is the auto-regressive part of the model. It allows us to incorporate the effect of past values into our model. Intuitively, this would be akin to stating that it is likely to be warm tomorrow if it has been warm the past 3 times.
d is the integrated part of the model. This includes terms in the model that incorporate the amount of differencing (i.e. the number of past time points to subtract from the actual ideal) to enlistly to the time series. Intuitively, this would be akin to stating that it is likely to be same temperature tomorrow if the disagreement in temperature in the last three times has been very tiny.
q is the moving normal part of the model. This allows us to set the error of our model as a bilinear combination of the error values observed at preceding time points in the past. When dealing with seasonal effects, we make use of the seasonal ARIMA, which is denoted as ARIMA(p,d,q)(P,D,Q)s. Here, (p, d, q) are the non-seasonal parameters described above, while (P, D, Q) follow the same definition but are enlisted to the seasonal element of the time series. The statement s is the regularity of the time series (4 for quarterly periods, 12 for yearly periods, etc.).
The seasonal ARIMA mode can be discouraging because of the aggregate tuning parameters involved. In the next portion, we will describe how to automate the processes of identifying the best set of parameters for the seasonal ARIMA time series model.
ARIMA stands for AutoregRessive Integrated Moving Average, and it’s a common method to model time series data where there is dependence among temporal values. SARIMA is a similar method that adds seasonality element to ARIMA. As shown below, user needs to specify some parameters to fit an ARIMA model within the Python statsmodel package (version 0.8).
The ARIMA parameters are (p,d,q):
p - the auto-regression term that comprises p number of past values to predict present value. For example, if p=2, then past values y(t-1), y(t-2) would be used to predict y(t).
d - the integrated part of the model. Generally d=1, corresponding to the difference between current value and previous one. If d >1, it means the differencing would be performed more than once (i.e., difference of prior d number of values and present value).
q - the Moving Average terms, which is used to generate the error terms of the model. This results in a linear combination of errors for the prior q data point, where each error is defined as the difference between the moving average value and the actual value at a given time point (t).
For SARIMA model, there’s also (P,D,Q,S) parameters specified along with the (p,d,q). The P,D,Q values are similar to the parameters described above but it’s applied to the seasonality componenet of the SARIMA model. S is the periodicity of the time series (4 for quarterly, 12 for yearly).
import statsmodels.api as sm
y_hat_avg = valid.copy()
fit2 = sm.tsa.statespace.SARIMAX(np.asarray(Train['Count']),order=(2, 1, 2),seasonal_order=(0,1,1,7)).fit()
y_hat_avg['arima'] = fit2.forecast(len(valid))
plt.figure(figsize=(15,5))
plt.plot(Train['Count'], label='Train')
plt.plot(valid['Count'], label='Valid')
plt.plot(y_hat_avg['arima'], label='arima')
test_yhat = df_test.copy()
test_yhat['test_arima'] = fit2.forecast(len(df_test))
#plt.plot(df_test['Count'], label='test')
#plt.plot(test_yhat['test_arima'], label='testarima')
plt.legend(loc='best')
plt.show()
print("r2_score >>>",r2_score(y_hat_avg['Count'], y_hat_avg['arima']))
print("mean_absolute_percentage_error >>>",mean_absolute_percentage_error(y_hat_avg['Count'], y_hat_avg['arima']))
print("median_absolute_error >>>",median_absolute_error(y_hat_avg['Count'], y_hat_avg['arima']))
print("mean_absolute_error >>>",mean_absolute_error(y_hat_avg['Count'], y_hat_avg['arima']))
print("mean_squared_error >>>",mean_squared_error(y_hat_avg['Count'], y_hat_avg['arima']))
print("mean_squared_log_error >>>",mean_squared_log_error(y_hat_avg['Count'], y_hat_avg['arima']))
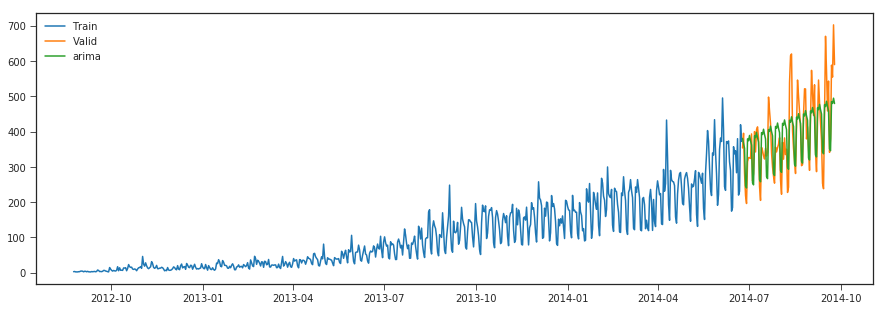
r2_score >>> 0.6179264938889601
mean_absolute_percentage_error >>> 13.832316408898384
median_absolute_error >>> 47.59288040566122
mean_absolute_error >>> 53.928107198396624
mean_squared_error >>> 4662.715485842272
mean_squared_log_error >>> 0.026348300266155537
The SARIMA model tends to capture both trend and seasonality better compared to other methods and is evident with the error metrics.Although we used the ACF and PACF plots to select the p,d,q parameters we would be better of with automatic selection of parameter through Auto ARIMA which selects the model by performing grid search of the paramters based on constraints provided and selects the best model with lowest AIC score.
from pyramid.arima import auto_arima
stepwise_model = auto_arima(Train['Count'], trace=True,start_p=0, start_q=0, start_P=0, start_Q=0,d=1,max_d=3,
max_p=3, max_q=3, max_P=2, max_Q=2, seasonal=True,
stepwise=False, suppress_warnings=True, D=1, max_D=2,m=7,
error_action='ignore',approximation = False)
Fit ARIMA: order=(0, 1, 0) seasonal_order=(0, 1, 0, 7); AIC=6511.215, BIC=6520.202, Fit time=0.042 seconds
Fit ARIMA: order=(0, 1, 0) seasonal_order=(0, 1, 1, 7); AIC=6214.605, BIC=6228.086, Fit time=0.266 seconds
Fit ARIMA: order=(0, 1, 0) seasonal_order=(0, 1, 2, 7); AIC=6213.677, BIC=6231.652, Fit time=0.853 seconds
Fit ARIMA: order=(0, 1, 0) seasonal_order=(1, 1, 0, 7); AIC=6390.441, BIC=6403.922, Fit time=0.304 seconds
Fit ARIMA: order=(0, 1, 0) seasonal_order=(1, 1, 1, 7); AIC=6214.193, BIC=6232.168, Fit time=0.451 seconds
Fit ARIMA: order=(0, 1, 0) seasonal_order=(1, 1, 2, 7); AIC=6215.042, BIC=6237.510, Fit time=1.700 seconds
Fit ARIMA: order=(0, 1, 0) seasonal_order=(2, 1, 0, 7); AIC=6333.753, BIC=6351.728, Fit time=0.686 seconds
Fit ARIMA: order=(0, 1, 0) seasonal_order=(2, 1, 1, 7); AIC=6210.945, BIC=6233.414, Fit time=1.293 seconds
Fit ARIMA: order=(0, 1, 0) seasonal_order=(2, 1, 2, 7); AIC=6198.921, BIC=6225.883, Fit time=3.608 seconds
Fit ARIMA: order=(0, 1, 1) seasonal_order=(0, 1, 0, 7); AIC=6411.497, BIC=6424.978, Fit time=0.229 seconds
Fit ARIMA: order=(0, 1, 1) seasonal_order=(0, 1, 1, 7); AIC=6089.620, BIC=6107.595, Fit time=0.546 seconds
Fit ARIMA: order=(0, 1, 1) seasonal_order=(0, 1, 2, 7); AIC=6091.611, BIC=6114.080, Fit time=1.152 seconds
Fit ARIMA: order=(0, 1, 1) seasonal_order=(1, 1, 0, 7); AIC=6251.395, BIC=6269.370, Fit time=0.598 seconds
Fit ARIMA: order=(0, 1, 1) seasonal_order=(1, 1, 1, 7); AIC=6091.612, BIC=6114.080, Fit time=0.838 seconds
Fit ARIMA: order=(0, 1, 1) seasonal_order=(1, 1, 2, 7); AIC=6090.353, BIC=6117.316, Fit time=2.621 seconds
Fit ARIMA: order=(0, 1, 1) seasonal_order=(2, 1, 0, 7); AIC=6212.019, BIC=6234.488, Fit time=1.285 seconds
Fit ARIMA: order=(0, 1, 1) seasonal_order=(2, 1, 1, 7); AIC=6093.135, BIC=6120.097, Fit time=1.389 seconds
Fit ARIMA: order=(0, 1, 1) seasonal_order=(2, 1, 2, 7); AIC=6090.251, BIC=6121.707, Fit time=2.191 seconds
Fit ARIMA: order=(0, 1, 2) seasonal_order=(0, 1, 0, 7); AIC=6317.983, BIC=6335.958, Fit time=0.922 seconds
Fit ARIMA: order=(0, 1, 2) seasonal_order=(0, 1, 1, 7); AIC=6032.861, BIC=6055.330, Fit time=1.430 seconds
Fit ARIMA: order=(0, 1, 2) seasonal_order=(0, 1, 2, 7); AIC=6034.020, BIC=6060.983, Fit time=3.711 seconds
Fit ARIMA: order=(0, 1, 2) seasonal_order=(1, 1, 0, 7); AIC=6188.997, BIC=6211.466, Fit time=1.679 seconds
Fit ARIMA: order=(0, 1, 2) seasonal_order=(1, 1, 1, 7); AIC=6034.120, BIC=6061.083, Fit time=1.952 seconds
Fit ARIMA: order=(0, 1, 2) seasonal_order=(1, 1, 2, 7); AIC=6055.293, BIC=6086.749, Fit time=4.743 seconds
Fit ARIMA: order=(0, 1, 2) seasonal_order=(2, 1, 0, 7); AIC=6152.656, BIC=6179.618, Fit time=3.682 seconds
Fit ARIMA: order=(0, 1, 2) seasonal_order=(2, 1, 1, 7); AIC=6034.164, BIC=6065.620, Fit time=2.366 seconds
Fit ARIMA: order=(0, 1, 2) seasonal_order=(2, 1, 2, 7); AIC=6036.226, BIC=6072.176, Fit time=7.124 seconds
Fit ARIMA: order=(0, 1, 3) seasonal_order=(0, 1, 0, 7); AIC=6306.374, BIC=6328.842, Fit time=0.588 seconds
Fit ARIMA: order=(0, 1, 3) seasonal_order=(0, 1, 1, 7); AIC=6032.172, BIC=6059.135, Fit time=2.063 seconds
Fit ARIMA: order=(0, 1, 3) seasonal_order=(0, 1, 2, 7); AIC=6040.641, BIC=6072.097, Fit time=3.009 seconds
Fit ARIMA: order=(0, 1, 3) seasonal_order=(1, 1, 0, 7); AIC=6184.301, BIC=6211.264, Fit time=0.834 seconds
Fit ARIMA: order=(0, 1, 3) seasonal_order=(1, 1, 1, 7); AIC=6031.443, BIC=6062.899, Fit time=1.798 seconds
Fit ARIMA: order=(0, 1, 3) seasonal_order=(1, 1, 2, 7); AIC=6042.560, BIC=6078.510, Fit time=4.343 seconds
Fit ARIMA: order=(0, 1, 3) seasonal_order=(2, 1, 0, 7); AIC=6145.279, BIC=6176.736, Fit time=3.838 seconds
Fit ARIMA: order=(0, 1, 3) seasonal_order=(2, 1, 1, 7); AIC=6030.977, BIC=6066.927, Fit time=3.452 seconds
Fit ARIMA: order=(0, 1, 3) seasonal_order=(2, 1, 2, 7); AIC=6041.832, BIC=6082.275, Fit time=6.008 seconds
Fit ARIMA: order=(1, 1, 0) seasonal_order=(0, 1, 0, 7); AIC=6468.316, BIC=6481.797, Fit time=0.209 seconds
Fit ARIMA: order=(1, 1, 0) seasonal_order=(0, 1, 1, 7); AIC=6169.865, BIC=6187.840, Fit time=0.470 seconds
Fit ARIMA: order=(1, 1, 0) seasonal_order=(0, 1, 2, 7); AIC=6169.580, BIC=6192.049, Fit time=1.099 seconds
Fit ARIMA: order=(1, 1, 0) seasonal_order=(1, 1, 0, 7); AIC=6339.902, BIC=6357.877, Fit time=0.407 seconds
Fit ARIMA: order=(1, 1, 0) seasonal_order=(1, 1, 1, 7); AIC=6169.909, BIC=6192.377, Fit time=0.647 seconds
Fit ARIMA: order=(1, 1, 0) seasonal_order=(1, 1, 2, 7); AIC=6171.249, BIC=6198.212, Fit time=1.842 seconds
Fit ARIMA: order=(1, 1, 0) seasonal_order=(2, 1, 0, 7); AIC=6289.992, BIC=6312.460, Fit time=1.019 seconds
Fit ARIMA: order=(1, 1, 0) seasonal_order=(2, 1, 1, 7); AIC=6168.306, BIC=6195.268, Fit time=1.395 seconds
Fit ARIMA: order=(1, 1, 0) seasonal_order=(2, 1, 2, 7); AIC=6172.686, BIC=6204.142, Fit time=3.826 seconds
Fit ARIMA: order=(1, 1, 1) seasonal_order=(0, 1, 0, 7); AIC=6303.569, BIC=6321.544, Fit time=0.988 seconds
Fit ARIMA: order=(1, 1, 1) seasonal_order=(0, 1, 1, 7); AIC=6028.804, BIC=6051.272, Fit time=1.361 seconds
Fit ARIMA: order=(1, 1, 1) seasonal_order=(0, 1, 2, 7); AIC=6027.098, BIC=6054.061, Fit time=2.868 seconds
Fit ARIMA: order=(1, 1, 1) seasonal_order=(1, 1, 0, 7); AIC=6178.935, BIC=6201.404, Fit time=1.575 seconds
Fit ARIMA: order=(1, 1, 1) seasonal_order=(1, 1, 1, 7); AIC=6027.467, BIC=6054.430, Fit time=2.375 seconds
Fit ARIMA: order=(1, 1, 1) seasonal_order=(1, 1, 2, 7); AIC=6028.978, BIC=6060.435, Fit time=3.834 seconds
Fit ARIMA: order=(1, 1, 1) seasonal_order=(2, 1, 0, 7); AIC=6137.960, BIC=6164.922, Fit time=3.761 seconds
Fit ARIMA: order=(1, 1, 1) seasonal_order=(2, 1, 1, 7); AIC=6027.242, BIC=6058.698, Fit time=3.920 seconds
Fit ARIMA: order=(1, 1, 1) seasonal_order=(2, 1, 2, 7); AIC=6029.132, BIC=6065.082, Fit time=4.382 seconds
Fit ARIMA: order=(1, 1, 2) seasonal_order=(0, 1, 0, 7); AIC=6304.469, BIC=6326.938, Fit time=1.444 seconds
Fit ARIMA: order=(1, 1, 2) seasonal_order=(0, 1, 1, 7); AIC=6029.946, BIC=6056.909, Fit time=1.706 seconds
Fit ARIMA: order=(1, 1, 2) seasonal_order=(0, 1, 2, 7); AIC=6028.280, BIC=6059.736, Fit time=4.672 seconds
Fit ARIMA: order=(1, 1, 2) seasonal_order=(1, 1, 0, 7); AIC=6180.615, BIC=6207.578, Fit time=1.953 seconds
Fit ARIMA: order=(1, 1, 2) seasonal_order=(1, 1, 1, 7); AIC=6028.660, BIC=6060.116, Fit time=2.410 seconds
Fit ARIMA: order=(1, 1, 2) seasonal_order=(1, 1, 2, 7); AIC=6030.471, BIC=6066.421, Fit time=5.336 seconds
Fit ARIMA: order=(1, 1, 2) seasonal_order=(2, 1, 0, 7); AIC=6139.700, BIC=6171.156, Fit time=4.193 seconds
Fit ARIMA: order=(1, 1, 2) seasonal_order=(2, 1, 1, 7); AIC=6028.336, BIC=6064.286, Fit time=4.791 seconds
Fit ARIMA: order=(1, 1, 2) seasonal_order=(2, 1, 2, 7); AIC=6030.414, BIC=6070.858, Fit time=5.870 seconds
Fit ARIMA: order=(1, 1, 3) seasonal_order=(0, 1, 0, 7); AIC=6275.370, BIC=6302.333, Fit time=1.574 seconds
Fit ARIMA: order=(1, 1, 3) seasonal_order=(0, 1, 1, 7); AIC=6034.485, BIC=6065.941, Fit time=3.142 seconds
Fit ARIMA: order=(1, 1, 3) seasonal_order=(0, 1, 2, 7); AIC=6033.452, BIC=6069.402, Fit time=6.413 seconds
Fit ARIMA: order=(1, 1, 3) seasonal_order=(1, 1, 0, 7); AIC=6181.611, BIC=6213.068, Fit time=2.898 seconds
Fit ARIMA: order=(1, 1, 3) seasonal_order=(1, 1, 1, 7); AIC=6033.420, BIC=6069.370, Fit time=3.524 seconds
Fit ARIMA: order=(1, 1, 3) seasonal_order=(1, 1, 2, 7); AIC=6038.512, BIC=6078.955, Fit time=7.005 seconds
Fit ARIMA: order=(1, 1, 3) seasonal_order=(2, 1, 0, 7); AIC=6143.273, BIC=6179.223, Fit time=5.036 seconds
Fit ARIMA: order=(1, 1, 3) seasonal_order=(2, 1, 1, 7); AIC=6032.628, BIC=6073.072, Fit time=4.519 seconds
Fit ARIMA: order=(1, 1, 3) seasonal_order=(2, 1, 2, 7); AIC=6049.790, BIC=6094.727, Fit time=7.930 seconds
Fit ARIMA: order=(2, 1, 0) seasonal_order=(0, 1, 0, 7); AIC=6409.165, BIC=6427.140, Fit time=0.330 seconds
Fit ARIMA: order=(2, 1, 0) seasonal_order=(0, 1, 1, 7); AIC=6098.125, BIC=6120.594, Fit time=0.690 seconds
Fit ARIMA: order=(2, 1, 0) seasonal_order=(0, 1, 2, 7); AIC=6099.865, BIC=6126.827, Fit time=1.379 seconds
Fit ARIMA: order=(2, 1, 0) seasonal_order=(1, 1, 0, 7); AIC=6251.522, BIC=6273.991, Fit time=0.658 seconds
Fit ARIMA: order=(2, 1, 0) seasonal_order=(1, 1, 1, 7); AIC=6099.883, BIC=6126.845, Fit time=1.029 seconds
Fit ARIMA: order=(2, 1, 0) seasonal_order=(1, 1, 2, 7); AIC=6101.823, BIC=6133.279, Fit time=2.709 seconds
Fit ARIMA: order=(2, 1, 0) seasonal_order=(2, 1, 0, 7); AIC=6206.316, BIC=6233.278, Fit time=1.076 seconds
Fit ARIMA: order=(2, 1, 0) seasonal_order=(2, 1, 1, 7); AIC=6101.218, BIC=6132.674, Fit time=1.908 seconds
Fit ARIMA: order=(2, 1, 0) seasonal_order=(2, 1, 2, 7); AIC=6101.586, BIC=6137.536, Fit time=2.528 seconds
Fit ARIMA: order=(2, 1, 1) seasonal_order=(0, 1, 0, 7); AIC=6304.855, BIC=6327.324, Fit time=0.636 seconds
Fit ARIMA: order=(2, 1, 1) seasonal_order=(0, 1, 1, 7); AIC=6030.463, BIC=6057.426, Fit time=1.649 seconds
Fit ARIMA: order=(2, 1, 1) seasonal_order=(0, 1, 2, 7); AIC=6028.717, BIC=6060.174, Fit time=3.513 seconds
Fit ARIMA: order=(2, 1, 1) seasonal_order=(1, 1, 0, 7); AIC=6180.848, BIC=6207.811, Fit time=2.282 seconds
Fit ARIMA: order=(2, 1, 1) seasonal_order=(1, 1, 1, 7); AIC=6029.100, BIC=6060.556, Fit time=2.566 seconds
Fit ARIMA: order=(2, 1, 1) seasonal_order=(1, 1, 2, 7); AIC=6030.668, BIC=6066.618, Fit time=4.419 seconds
Fit ARIMA: order=(2, 1, 1) seasonal_order=(2, 1, 0, 7); AIC=6139.877, BIC=6171.333, Fit time=3.592 seconds
Fit ARIMA: order=(2, 1, 1) seasonal_order=(2, 1, 1, 7); AIC=6028.781, BIC=6064.731, Fit time=4.106 seconds
Fit ARIMA: order=(2, 1, 1) seasonal_order=(2, 1, 2, 7); AIC=6030.818, BIC=6071.262, Fit time=4.868 seconds
Fit ARIMA: order=(2, 1, 2) seasonal_order=(0, 1, 0, 7); AIC=6350.890, BIC=6377.853, Fit time=1.173 seconds
Fit ARIMA: order=(2, 1, 2) seasonal_order=(0, 1, 1, 7); AIC=6036.361, BIC=6067.817, Fit time=1.416 seconds
Fit ARIMA: order=(2, 1, 2) seasonal_order=(0, 1, 2, 7); AIC=6033.922, BIC=6069.872, Fit time=4.592 seconds
Fit ARIMA: order=(2, 1, 2) seasonal_order=(1, 1, 0, 7); AIC=6182.588, BIC=6214.045, Fit time=2.731 seconds
Fit ARIMA: order=(2, 1, 2) seasonal_order=(1, 1, 1, 7); AIC=6034.224, BIC=6070.174, Fit time=2.717 seconds
Fit ARIMA: order=(2, 1, 2) seasonal_order=(1, 1, 2, 7); AIC=6035.795, BIC=6076.239, Fit time=6.230 seconds
Fit ARIMA: order=(2, 1, 2) seasonal_order=(2, 1, 0, 7); AIC=6141.405, BIC=6177.355, Fit time=4.351 seconds
Fit ARIMA: order=(2, 1, 2) seasonal_order=(2, 1, 1, 7); AIC=6034.401, BIC=6074.844, Fit time=4.849 seconds
Fit ARIMA: order=(2, 1, 2) seasonal_order=(2, 1, 2, 7); AIC=6035.744, BIC=6080.682, Fit time=5.765 seconds
Fit ARIMA: order=(2, 1, 3) seasonal_order=(0, 1, 0, 7); AIC=6248.114, BIC=6279.570, Fit time=1.859 seconds
Fit ARIMA: order=(2, 1, 3) seasonal_order=(0, 1, 1, 7); AIC=6033.942, BIC=6069.892, Fit time=2.469 seconds
Fit ARIMA: order=(2, 1, 3) seasonal_order=(0, 1, 2, 7); AIC=6031.535, BIC=6071.979, Fit time=6.299 seconds
Fit ARIMA: order=(2, 1, 3) seasonal_order=(1, 1, 0, 7); AIC=6210.247, BIC=6246.197, Fit time=2.568 seconds
Fit ARIMA: order=(2, 1, 3) seasonal_order=(1, 1, 1, 7); AIC=6032.068, BIC=6072.512, Fit time=3.675 seconds
Fit ARIMA: order=(2, 1, 3) seasonal_order=(1, 1, 2, 7); AIC=6030.886, BIC=6075.823, Fit time=7.417 seconds
Fit ARIMA: order=(2, 1, 3) seasonal_order=(2, 1, 0, 7); AIC=6169.532, BIC=6209.976, Fit time=3.088 seconds
Fit ARIMA: order=(2, 1, 3) seasonal_order=(2, 1, 1, 7); AIC=6030.981, BIC=6075.919, Fit time=5.197 seconds
Fit ARIMA: order=(2, 1, 3) seasonal_order=(2, 1, 2, 7); AIC=6034.234, BIC=6083.665, Fit time=7.573 seconds
Fit ARIMA: order=(3, 1, 0) seasonal_order=(0, 1, 0, 7); AIC=6376.496, BIC=6398.965, Fit time=0.407 seconds
Fit ARIMA: order=(3, 1, 0) seasonal_order=(0, 1, 1, 7); AIC=6076.235, BIC=6103.198, Fit time=0.789 seconds
Fit ARIMA: order=(3, 1, 0) seasonal_order=(0, 1, 2, 7); AIC=6077.302, BIC=6108.759, Fit time=1.965 seconds
Fit ARIMA: order=(3, 1, 0) seasonal_order=(1, 1, 0, 7); AIC=6226.627, BIC=6253.589, Fit time=0.815 seconds
Fit ARIMA: order=(3, 1, 0) seasonal_order=(1, 1, 1, 7); AIC=6077.357, BIC=6108.813, Fit time=1.249 seconds
Fit ARIMA: order=(3, 1, 0) seasonal_order=(1, 1, 2, 7); AIC=6079.274, BIC=6115.225, Fit time=3.318 seconds
Fit ARIMA: order=(3, 1, 0) seasonal_order=(2, 1, 0, 7); AIC=6188.337, BIC=6219.794, Fit time=1.671 seconds
Fit ARIMA: order=(3, 1, 0) seasonal_order=(2, 1, 1, 7); AIC=6078.728, BIC=6114.678, Fit time=2.432 seconds
Fit ARIMA: order=(3, 1, 0) seasonal_order=(2, 1, 2, 7); AIC=6077.524, BIC=6117.968, Fit time=3.851 seconds
Fit ARIMA: order=(3, 1, 1) seasonal_order=(0, 1, 0, 7); AIC=6378.317, BIC=6405.279, Fit time=0.816 seconds
Fit ARIMA: order=(3, 1, 1) seasonal_order=(0, 1, 1, 7); AIC=6020.087, BIC=6051.543, Fit time=2.688 seconds
Fit ARIMA: order=(3, 1, 1) seasonal_order=(0, 1, 2, 7); AIC=6020.166, BIC=6056.116, Fit time=3.575 seconds
Fit ARIMA: order=(3, 1, 1) seasonal_order=(1, 1, 0, 7); AIC=6163.711, BIC=6195.167, Fit time=2.832 seconds
Fit ARIMA: order=(3, 1, 1) seasonal_order=(1, 1, 1, 7); AIC=6020.330, BIC=6056.280, Fit time=2.507 seconds
Fit ARIMA: order=(3, 1, 1) seasonal_order=(1, 1, 2, 7); AIC=6022.149, BIC=6062.593, Fit time=4.923 seconds
Fit ARIMA: order=(3, 1, 1) seasonal_order=(2, 1, 0, 7); AIC=6123.174, BIC=6159.125, Fit time=5.504 seconds
Fit ARIMA: order=(3, 1, 1) seasonal_order=(2, 1, 1, 7); AIC=6021.463, BIC=6061.906, Fit time=6.661 seconds
Fit ARIMA: order=(3, 1, 1) seasonal_order=(2, 1, 2, 7); AIC=6021.561, BIC=6066.498, Fit time=6.390 seconds
Fit ARIMA: order=(3, 1, 2) seasonal_order=(0, 1, 0, 7); AIC=6306.830, BIC=6338.286, Fit time=1.913 seconds
Fit ARIMA: order=(3, 1, 2) seasonal_order=(0, 1, 1, 7); AIC=6038.323, BIC=6074.273, Fit time=2.618 seconds
Fit ARIMA: order=(3, 1, 2) seasonal_order=(0, 1, 2, 7); AIC=6035.906, BIC=6076.350, Fit time=5.961 seconds
Fit ARIMA: order=(3, 1, 2) seasonal_order=(1, 1, 0, 7); AIC=6184.553, BIC=6220.503, Fit time=2.978 seconds
Fit ARIMA: order=(3, 1, 2) seasonal_order=(1, 1, 1, 7); AIC=6036.178, BIC=6076.622, Fit time=2.938 seconds
Fit ARIMA: order=(3, 1, 2) seasonal_order=(1, 1, 2, 7); AIC=6037.841, BIC=6082.779, Fit time=4.326 seconds
Fit ARIMA: order=(3, 1, 2) seasonal_order=(2, 1, 0, 7); AIC=6143.035, BIC=6183.479, Fit time=6.413 seconds
Fit ARIMA: order=(3, 1, 2) seasonal_order=(2, 1, 1, 7); AIC=6036.581, BIC=6081.519, Fit time=6.486 seconds
Fit ARIMA: order=(3, 1, 2) seasonal_order=(2, 1, 2, 7); AIC=6037.715, BIC=6087.147, Fit time=7.734 seconds
Fit ARIMA: order=(3, 1, 3) seasonal_order=(0, 1, 0, 7); AIC=nan, BIC=nan, Fit time=nan seconds
Fit ARIMA: order=(3, 1, 3) seasonal_order=(0, 1, 1, 7); AIC=nan, BIC=nan, Fit time=nan seconds
Fit ARIMA: order=(3, 1, 3) seasonal_order=(0, 1, 2, 7); AIC=nan, BIC=nan, Fit time=nan seconds
Fit ARIMA: order=(3, 1, 3) seasonal_order=(1, 1, 0, 7); AIC=nan, BIC=nan, Fit time=nan seconds
Fit ARIMA: order=(3, 1, 3) seasonal_order=(1, 1, 1, 7); AIC=nan, BIC=nan, Fit time=nan seconds
Fit ARIMA: order=(3, 1, 3) seasonal_order=(1, 1, 2, 7); AIC=nan, BIC=nan, Fit time=nan seconds
Fit ARIMA: order=(3, 1, 3) seasonal_order=(2, 1, 0, 7); AIC=nan, BIC=nan, Fit time=nan seconds
Fit ARIMA: order=(3, 1, 3) seasonal_order=(2, 1, 1, 7); AIC=nan, BIC=nan, Fit time=nan seconds
Fit ARIMA: order=(3, 1, 3) seasonal_order=(2, 1, 2, 7); AIC=nan, BIC=nan, Fit time=nan seconds
Total fit time: 391.715 seconds
print(stepwise_model.aic())
6020.086526482221
stepwise_model.fit(Train['Count'])
ARIMA(callback=None, disp=0, maxiter=50, method=None, order=(3, 1, 1),
out_of_sample_size=0, scoring='mse', scoring_args={},
seasonal_order=(0, 1, 1, 7), solver='lbfgs', start_params=None,
suppress_warnings=True, transparams=True, trend='c')
y_hat_avg1 = valid.copy()
y_hat_avg1['auto_arima'] = stepwise_model.predict(len(valid))
plt.figure(figsize=(15,5))
plt.plot(Train['Count'], label='Train')
plt.plot(valid['Count'], label='Valid')
plt.plot(y_hat_avg1['auto_arima'], label='auto_arima')
[<matplotlib.lines.Line2D at 0x7f0c19b72cf8>]
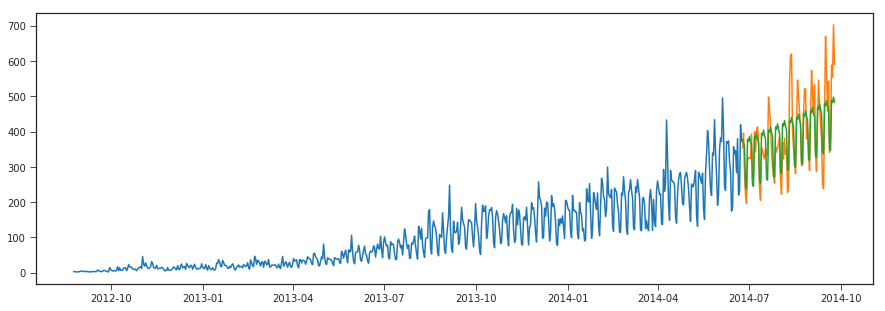
print("r2_score >>>",r2_score(y_hat_avg1['Count'], y_hat_avg1['auto_arima']))
print("mean_absolute_percentage_error >>>",mean_absolute_percentage_error(y_hat_avg1['Count'], y_hat_avg1['auto_arima']))
print("median_absolute_error >>>",median_absolute_error(y_hat_avg1['Count'], y_hat_avg1['auto_arima']))
print("mean_absolute_error >>>",mean_absolute_error(y_hat_avg1['Count'], y_hat_avg1['auto_arima']))
print("mean_squared_error >>>",mean_squared_error(y_hat_avg1['Count'], y_hat_avg1['auto_arima']))
print("mean_squared_log_error >>>",mean_squared_log_error(y_hat_avg1['Count'], y_hat_avg1['auto_arima']))
r2_score >>> 0.6251531643444177
mean_absolute_percentage_error >>> 13.58484603152323
median_absolute_error >>> 45.41053596424729
mean_absolute_error >>> 53.25297097623328
mean_squared_error >>> 4574.523272289658
mean_squared_log_error >>> 0.025711313858484044
The auto arima method tends to improve a little from our previous methods by automatic selection of paramters.